本地模型选择
总结一些在本地模型选择上的经验,在语言、领域、参数、评分、微调、量化等方面进行展开介绍。

选择一个模型,最终是为了满足用户在某些特定领域的需求,解决用户在这些方面的实际问题。
在开始的时候,可以先从比较知名的基座模型中选择几个体验一下,在体验的过程中发现模型的特点,然后与模型介绍中的参数进行对照,通过体验来更深刻的理解参数的意义。等到有了特定的需求,就可以根据前面积累的经验进行更有针对性的选择。
以下是我总结一些经验,我将从语言、专业领域、参数规模、评分、指令微调、量化等方面进行介绍:
语言
大语言模型基本上都是懂中文的,它可以理解用户的中文输入,但是其内部思考逻辑却是英文,因此不少模型在用户进行中文提问时,仍然会以英文作答,即使你要求其用中文回应,也会夹杂着一些英文输出。因此,如果对中文对话有要求的话,选择国内公司开发的模型就会好一些,尤其在古汉语、历史、地理、文旅方面会有明显的优势。
比如向大模型提问:“李白最知名的诗是哪首,内容是什么?”
这是 phi3 回答,明显很糟糕。不过它的设计目标已经明确说明了是在英文语境下进行商业和研究用途,所以自然不会针对中文进行特定优化,这糟糕也就不难理解了。不过从形式上来看,它应该是能区分诗和普通对话的,另外诗作部分的内容也有很明显的“中译英译中”的味道。

Llama3.1 的回答稍微好那么一点,但不多,前面部分还过得去,但是“床前明月光”之后的内容就是完全是AI自己发挥的了。

Qwen2 的回答明显好多了,先不论“静夜思”和“将敬酒”哪首更广为人知,至少诗的内容没有背错,而且还主动给你加了一段“阅读理解”,不得不说非常符合中文习惯。

所以如果是用来提供中文语境下的简单陪聊或者文章总结,使用国产模型还是有很明显的优势的。
专业领域
然后,就是要考虑特定的行业,比如在编程、医疗领域,有很多开源模型可以使用,这些模型有独立训练的,也有在大公司的开源基座模型上进行二次训练得到的,第二种方式可以大大降低训练成本和训练所需要的时间。
这些专用模型在各自专业领域的知识储备要比通用模型强大很多,在模型体积不明显增加的前提下,非常明显的提升该领域的能力,部分模型还会通过针对性的进行优化来提升响应速度,使其在资源有限的个人电脑也能达到顶尖商业模型的水准。
在编程领域,有基于 llama 的 codellama,基于 gemma 的 codegemma ,基于 qwen 的 codeqwen 等,都是在基座模型上针对编程能力进行了专门的强化的例子。
而回到前文提到的古汉语领域,也有基于 qwen 的 荀子 模型。
关键指标
在确定领域之后,我们还会发现,在同一领域,也会有多个模型可以选择,甚至同一个模型也会有很多不同的规格,这个时候,就需要我们能够理解这些规格参数分别是什么意思,并参照模型的评分来缩小选择的范围,在圈定一小批候选名单后,再把这些模型下载下来进行实际的体验,最终决定采用哪个模型。
参数规模
对于本地运行来说,所有规格中,影响最大的应该要属参数规模了。
以 qwen2 为例,有 0.5B、1.5B、7B、72B 四种规模,这里的B是billion的缩写,7B 就是用了70亿个参数的意思。
大模型是基于神经网络的,计算机中的神经网络模拟了生物大脑的运作方式,生物的神经元之间有神经连接,这些连接有强有弱,计算机科学家用参数来模拟生物中神经连接的强弱,因此在采用相似的神经网络结构的情况下,参数规模越大,神经连接就越丰富,其学习潜力就越大。把学习资料输入到网络中对其进行训练,随着数据的不断输入,这些参数也随之不断调整,等训练完成后,这些参数被确定下来,就成了模型。
因此,参数的规模首先就决定了模型文件的大小和运行时所需要的内存或者显存,这两个是硬性指标,如果硬盘存不下,或内存显存不够用,模型就会直接无法运行或在运行过程中异常退出。
然后,参数还会明显的影响运行速度,因为运行过程中,数据每多经过一个神经连接,就要多进行一次计算,相应的就需要CPU或GPU执行更多的指令,参数规模越大,计算就越慢。
虽然有压缩、剪枝等方法进行优化,但更大规模参数消耗更多资源的规律是不变的。
一般情况下个人电脑是无法全速运行72B模型的(需要至少2张3090/4090显卡),通过把数据放在内存的方法,可以用单张显卡勉强运行,但是响应速度大打折扣,实际意义不大。因此一般选择7B模型即可,对于其他模型,有14B等规格的,可以根据自己的电脑配置进行判断,一般14B需要大约8G显存。
评分
上面已经说过,参数规模决定模型的“重量级”,不同“重量级”的选手自然不适合放在一起比较,在模型的介绍页面,通常可以看到该模型和其他模型的得分比较。
还是以 Qwen2 为例,官方为Qwen2-7B选择的参照模型是 Llama3-8B 和 GLM4-9B。可以看到Qwen 在除了 MMLU 和 MATH 之外都得到了最高的分数。这时候就要结合你的实际需要,如果你想找个通用的聊天机器人,可以选 Qwen-7B ,如果你就是要用来解决数学问题的,则应该优先考虑 GLM4-9B。

竞技场
但是只根据评分进行判断,还会遇到一个问题,就是评分并不能完全代表模型的能力。
首先评分本身不能替代日常的使用场景,用户会有自己的使用偏好,与模型交互的问题会有一定的侧重和倾向,不会与测试问题所占的比重重合。
另外模型也会针对测试进行了专门的优化,就像以前手机硬件跑分一样,有些厂家会联合跑分软件进行针对性的优化,优化过的比没优化过的自然表现更好。
这时候,就引入了竞技场这种人工评判的方式,由人类用户直接进行提问,然后不同的模型同时给出回答,人类用户对回答进行评价,赢的模型加分输的模型扣分(当然,人类用户在评价时是不能知道答案是哪个模型给出的)。最后根据一定规则,按照积分和胜率等进行排名。
所以你也可以根据竞技场的排名来作为选择的参考,比如司南评测。
竞技场更多的是对各家厂商顶级规格的模型进行评测,不太关注小模型,在帮助你选择云服务商时会更有价值。对于本地运行小模型来说,它的参考意义就是你能大概知道哪家的得分水分比较大。
指令微调和量化
假设我们已经决定了使用 Qwen2-7B,但是当你打开 ollama 的下载界面,你会发现即使是同一个参数规模,也有很多不同的分支可以选择。
通过版本编号,可以看出来默认的 7b 实际上就是 7b-instruct-q4_0。
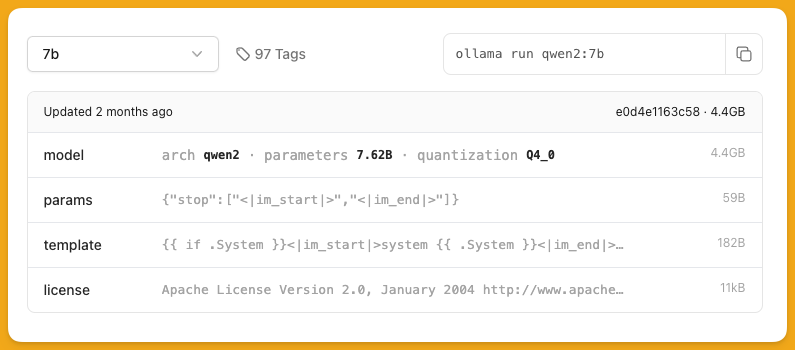
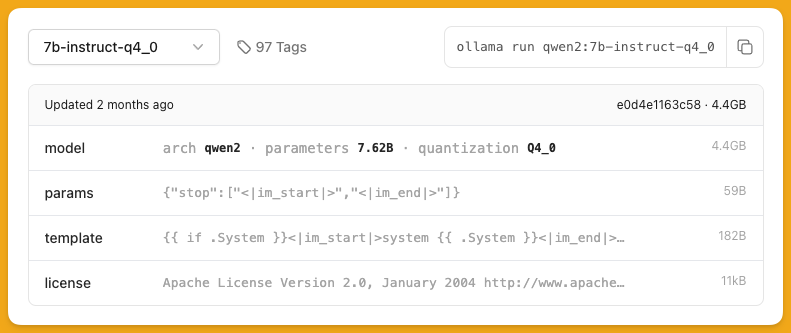
指令微调
如果打开下拉菜单,你会看到与 instruct 对应的是 text ,在有些模型里,也有带 chat 的分支。一般个人使用选择 instruct,这是经过指令微调的版本,能够更好的理解人类语言的输入并以更符合人类语言习惯的方式进行输出。
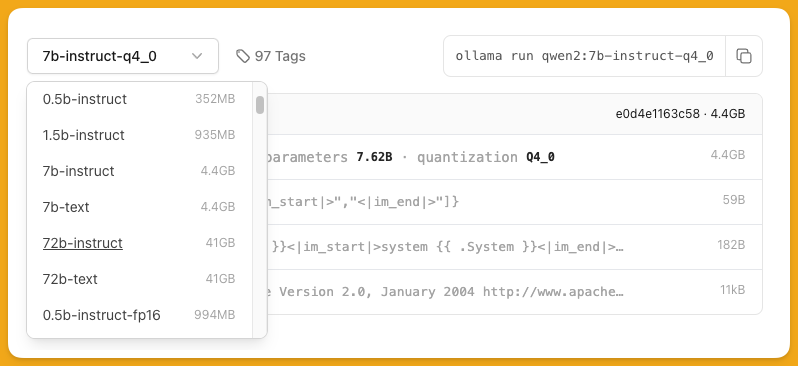
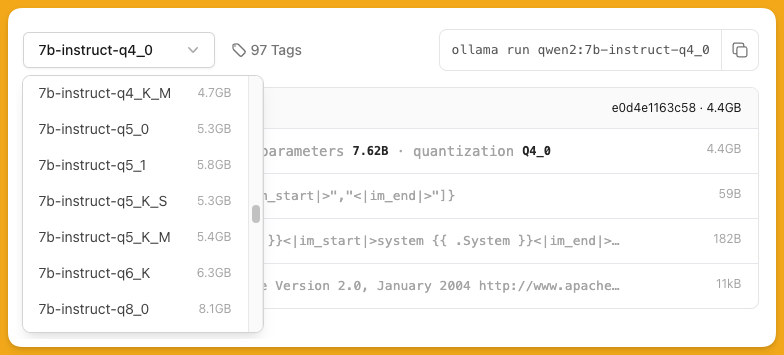
量化
模型在一开始训练出来时,其精度是16位浮点的,也就是说每个参数的精度是16位的,通常标记成 fp16。为了节约计算资源,提高计算速度,会进行量化操作,也就是通过牺牲计算精度来减少硬盘和内存的使用,或是确保模型能完全加载到显存中来大幅提高运行速度,就像我们在计算圆的面积时会用3.14来代替π。
在选择模型时,你可以通过量化参数来进行更灵活的调整,比如你的电脑足够运行14B的模型,但是 Qwen2只提供了7B和72B的模型,没有中间的选项,这个时候,为了更充分的利用资源,你可以选择 7B 的 q6 或者 q8 版本,相对而言,他们的能力会比默认的 q4 模型更强,同时也仍然能在你的硬件上运行。同理,在你的硬件差那么点的时候,也可以反过来选择 q3 甚至 q2 模型(但是通常不建议这么做,q4 基本上是可以接受的下限,再往下会发生明显可感的降智)。
总结
本文说明了选择在本地选择大模型时要考虑的一些因素,先从语言支持、专业领域、参数规模等关键因素入手,然后介绍了如何通过评分和竞技场对模型进行评价,最后介绍指令调优和量化的概念,希望能对读者选择模型带来一些帮助。

