我的第一个MCP,以及开发过程中的经验感悟
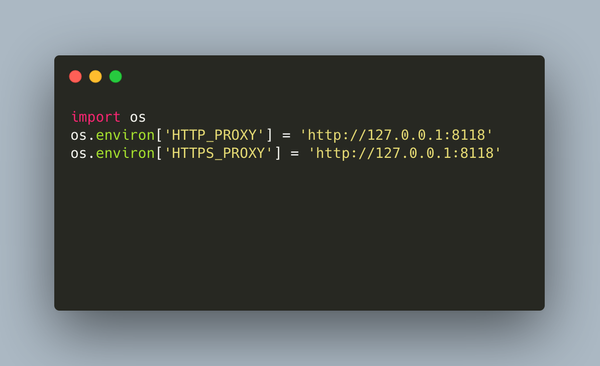
起心动念 上周开发完 sheetex 后,发了条朋友圈。有小伙伴建议搞个 MCP 玩,正好我本来也想学,于是这周就花了一天完成了 sheetex-mcp-server,一个将对话中生成的表格保存成 Excel 的 MCP 服务。 做之前快速调查了一下 smithery 和 modelscope ,发现已经有好几个 Excel 相关的:实现上既有调用本机上的 Office 软件进行操作的,也有用库读写文件的;功能就更加眼花缭乱,从简单读写数据,到插入图表,甚至可以截图保存。 看来是打不过了,好在只是做个练习,开搞。 一天下来,学到不少东西,也填了好几个坑,本文以坑为主。 那么下面就按顺序来了。 新手上路 Build an MCP Server 是官方的教程,新手入门刚刚好,它通过调用天气相关的接口演示了 MCP Server 的开发过程。